Autor: David Martín Alvarez.
En pasados artículos nos hemos comenzado a familiarizar con términos y definiciones específicas en el mundo hacker. Poco a poco hemos ido conociendo diferentes aspectos sobre navegación segura por internet, sistemas críticos, tipos de personajes que nos podemos encontrar mientras navegamos (o que se introducen en nuestros sistemas sin que nos percatemos) y muchos otras cuestiones que poco a poco se van presentando.
Ahora vamos a hablar sobre los sitios en los cuales nos podemos introducir navegando por la web. RECOMENDAMOS QUE NO ENTRÉIS EN ESTOS SITIOS, SIMPLEMENTE AQUÍ LOS ENUMERAMOS y os comentamos cuales son las características de estos con objeto de que sepáis que existen. Para entrar en estos sitios debemos controlar perfectamente lo que hacemos, en caso contrario los más seguro que conseguiremos, en el mejor de los casos, es algún malware.
Lo primero que debemos de entender es que la web tal y como la conocemos se compone de una serie de sitios que están al alcance de todo el mundo y que en un principio los buscadores (Google, Yahoo, duckduckgo…) indexan. El término indexar, aunque suene un poco extraño viene a significar “crear un índice”. Explicado con un poco más de amplitud significa que los buscadores, gracias a una serie de robots que están continuamente recorriendo la web, crean un índice de estas (Se guardan estas páginas y sus características en sus Bases de Datos para que a la hora de realizar búsquedas estas sean eficientes). Una vez tenida en cuenta esta cuestión podemos pasar a saber que es la Deep Web.
Con Deep Web en un principio se englobaron los contenidos no indexables. Esto que suena un tanto extraño simplemente se refiere a los contenidos complicados de encontrar usando los buscadores que están al alcance de todos, principalmente porque los motores de búsqueda no pueden acceder a ellas y por tanto no las incluyen en sus Bases de Datos.
El uso de estos términos sufrió un punto de inflexión con el cierre de Silk Road, una web donde se podían comprar drogas. A esta web solo se podía acceder usando “aplicaciones especiales” TOR.
Para diferenciar la Darknet , Deep Web y Surface Web (Web superficial) tenemos que visualizar un iceberg. La parte superior, la cual se puede ver sin necesidad de bucear, tal y como te estarás imaginando es la Web Superficial. Si nos enfundáramos un traje de buceo y nos lanzáramos al agua lo que descubriríamos sería la Deep Web, y en lo más profundo y oscuro, la DarkWeeb (Que es parte de la DeepWeb).
Para que nos hagamos una idea del tamaño de la Web superficial y según https://www.worldwidewebsize.com es a fecha de finales del 2019 de unas 55 billones de páginas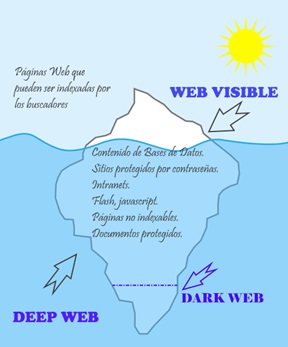 Web, y esto sigue sumando y sumando. Otra característica de esta red es que somos fácilmente identificables (y rastreables) a través de nuestra dirección IP (Algo así como una matrícula que nos asignan para navegar). Y es que a pesar de que no tengamos asignados una IP fija, sino una IP variable, la cual varía cada vez que nos conectamos a internet, los Proveedores de Internet la almacenan en sus Bases de Datos.
Web, y esto sigue sumando y sumando. Otra característica de esta red es que somos fácilmente identificables (y rastreables) a través de nuestra dirección IP (Algo así como una matrícula que nos asignan para navegar). Y es que a pesar de que no tengamos asignados una IP fija, sino una IP variable, la cual varía cada vez que nos conectamos a internet, los Proveedores de Internet la almacenan en sus Bases de Datos.
Además existen una serie de webs que aunque no son indexadas si son accesibles públicamente, tales como en el caso de facebook.
La Deep web es el 90% de la web, con las cifras anteriores pensar en el tamaño real de la web es realmente abrumador. Esta Deep web está formada por gran cantidad de información, la cual no tiene por que ser ilegal, los servicios de almacenamiento como Onedrive no son indexados, pero están compuestos por información personal de multitud de personas que lo más probable es que tengan multitud de documentos personales y fotos y videos familiares. La principal característica de esta zona de la web es que no es indexada por los motores habituales.
Además de esos servicios hay otras páginas accesibles por nosotros y que pertenecen a la Deep Web. Piensa que el contenido de una página que se genera automáticamente al realizar una consulta a una base de datos no va a ser indexada, pues estas página así generadas son temporales y solo existen mientras tú las consultes. (Por ejemplo si consultas el número de taxis libres en una zona determinada de tu ciudad en un momento determinado). Esta página forma parte de la Deep Web.
Otra parte de la Deep web la forman páginas que tienen indicado en el archivo robots.txt «Disallow» , es decir, deshabilitado. Ese archivo robots.txt está en el directorio principal de los sitios webs, y sirve para indicar a los indexadores que deben de realizar cuando visitan esa página. En este caso se les dice que hagan caso omiso del sitio.
Y un fragmento de la Deep Web es la Dark Web, en este caso hablamos de que son solo el 0,1% del total de la Web. Se trata de páginas Web que enmascaran sus direcciones IP y solo son accesibles a través de navegadores Web especiales. Estas páginas web tienen dominios .onion (TOR) o i2p (eepsites) y solo podremos acceder a ellas a través del software necesario. En el gráfico anterior podemos visualizar la Dark Web como el pico inferior del iceberg.
Estos sitios son indexados por indexadores especiales que a través de los cuales si que se logra realizar búsquedas en ella. En la Clearnet podemos buscar páginas .onion a través de una serie de webs que no mencionaré para no tentaros a entrar en ellos. Realmente estos buscadores son simples puentes entre la web normal y la Dark Web.
Y la Dark Web está compuesta por las Darknet (red oculta, recuerda que la Web es una de red de redes). Las darknets son las redes especiales (I2P o TOR), las cuales son las encargadas de albergar a todas esas páginas ocultas. ZeroNet , FreeNet o GnuNet son algunas de ellas, pero la más conocidas con diferencia es TOR.
 TOR significa The Onion Router (El router cebolla). La red TOR se presenta como una forma segura y anónima de navegar por la red lejos del control de gobiernos y grandes empresas que se enriquecen a costa de vigilar todo lo que realizamos mientras navegamos por la red. Esta red es anónima y distribuida (sus contenidos están albergados en diferentes sitios), de forma que nos podemos conectar de modo que no se pueda rastrear nuestra actividad.
TOR significa The Onion Router (El router cebolla). La red TOR se presenta como una forma segura y anónima de navegar por la red lejos del control de gobiernos y grandes empresas que se enriquecen a costa de vigilar todo lo que realizamos mientras navegamos por la red. Esta red es anónima y distribuida (sus contenidos están albergados en diferentes sitios), de forma que nos podemos conectar de modo que no se pueda rastrear nuestra actividad.
El motivo de usar una cebolla como parte de su nombre se debe a que estas tienen un montón de capas, y para acceder a una tenemos que eliminar la anterior, y a la inversa, para tapar una debemos cubrirla con otra capa completa. Siguiendo esa misma idea se logra encriptar la información que circula por esta red. Partiendo de la información original como núcleo, cada etapa en la encriptación crea la siguiente capa de la cebolla, y así hasta que se codificar los datos totalmente (Hemos creado una cebolla). Luego para desencriptar se realiza el proceso opuesto. Tenemos la cebolla y vamos accediendo a capas más interiores poco a poco hasta llegar a la información original, así la información está oculta.
Y por otro lado el método que usa para ocultar el origen y el fin de las comunicaciones consiste en realizar un enrulado “aleatorio”. De normal para comunicarse un punto A con un punto B se ha de pasar por unos nodos específicos, en TOR esos nodos no son los habituales, sino que se eligen de modo que su seguimiento sea complejo.
Con todas estas explicaciones espero haber aclarado algunos conceptos que nos permitirán comprender mejor los temas de seguridad informática. Por otro parte también nos permite tener una nueva perspectiva a la hora de percibir la web y conocer su extensión, la cual supongo os habrá sorprendido.